

数据结构与算法学习
数据结构与算法初识算法算法算法Algorithm是在有限时间内解决特定问题的一组指令或操作步骤
明确性:清晰输入输出
可行性:有限步骤、时间和内存空间下完成
结果确定性:相同的输入和运行下,输出相同
数据结构数据结构 Data Structure计算机组织和存储数据的方式
空间占用尽量减少,节省计算机内存
数据操作尽可能快速,涵盖数据访问、添加、删除、更新等
提供简洁的数据表示和逻辑信息,以便使得算法高效运行
数据结构与算法关系
数据结构是算法的基石。数据结构为算法提供结构化存储的数据,以及用于操作数据的方法
算法对数据结构结构化存储的数据进行操作。数据结构本身仅存储数据信息,需要结合算法才能解决特定问题
特定算法通常有对应最优的数据结构。算法通常可以基于不同的数据结构进行实现,但最终执行效率可能相差很大
数据结构就类似于积木组织形成,包括形状、大小、连接方式等。算法就是把积木拼成最终形态的一系列操作步骤。积木对应于数据,积木形状和连接方式代表数据结构,拼装积木的步骤则对应算法
复杂度算法设计追求层面
找到问题解法:算法需要在规定的输入范围内,可靠的求得问题的正确解
寻找 ...

Lambda表达式
Lambda表达式前言在日常开发中,我们很多时候需要用到Java 8的Lambda表达式,它允许把函数作为一个方法的参数,让我们的代码更优雅,更简洁。以下为常用的表达式写法。
.collect()用来起保存作用的函数
List转MapCollectors.toMap可以把一个List数组转成一个Map,代码如下
1234567891011121314151617public class TestLanbda { public static void main(String[] args) { List<UserInfo> userInfoList = new ArrayList<>(); userInfoList.add(new UserInfo(1L, "采蘑菇的小姑娘",18)); userInfoList.add(new UserInfo(2L, "程序员男孩", 22)); userInfoList.add(new Use ...
装饰者模式
装饰者模式概念装饰者模式也称为包装模式(Wrapper Pattern),属于结构型设计模式。该模式对客户端透明的方式来动态的扩展对象,(对扩展开发,对修改关闭)同时该模式也是继承关系的替代方法之一。总之该模式就是动态的给对象添加一些额外的职责,类似于我们点咖啡加糖加奶
装饰者模式的结构分为以下几类
抽象组件(Component):定义装饰方法的规范
被装饰者(ConcreteComponent):Component的具体实现,也就是我们要装饰的具体对象
装饰者组件(Decorator):持有组件(``)对象的实例引用,该类的职责就是为了装饰具体组件对象,定义的规范
具有装饰(ConcreteDecorator):负责给构件对象装饰附加的功能
装饰者和被装置者有相同的超类(Component)
你可以用一个或多个具体装饰(ConcreteDecorator)包装一个对象
装饰者可以在所委托被装饰者的行为之前与/ 或之后,加上自己的行为,以达到特点的目的(类似代理模式)
对象可以在任何时候被装饰,所以可以在运行时动态地、不限量的用你喜欢的装饰者来装饰对象
应用inputS ...
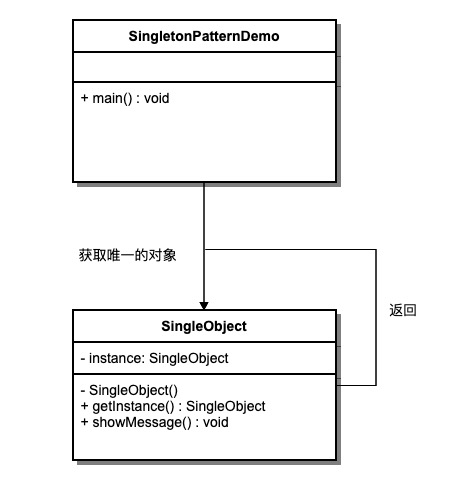
单例模式
单例模式概念
单例模式属于创建型模式,一个单例类在任何情况下都只存在一个实例,构造方法必须是私有的、由自己创建一个静态变量存储实例,对外提供一个静态公有方法获取实例。
优点是内存中只有一个实例,减少了开销,尤其是频繁的创建和销毁实例的情况下并且可以避免对资源的多重占用。缺点是没有抽象层,难以扩展,与单一职责原则冲突。
饿汉式饿汉式单例模式,顾名思义,类一加载就创建对象,这种方式比较常用。缺点
容易产生垃圾对象,浪费内存空间;
单例会在加载类后一开始就被初始化,即使客户端没有调用getInstance()方法。饿汉式的创建方式在一些场景中将无法使用:例如Singleton实例的创建是依赖参数或者配置文件的,在getInstance()之前必须调用某个方法设置参数给它,那样这种单例写法就无法使用。
优点线程安全,没有加锁,执行效率较高
12345678910public class Singleton { //1.私有化构造方法 private Singleton(){} //2.定义一个静态变量指向自己类型 private f ...
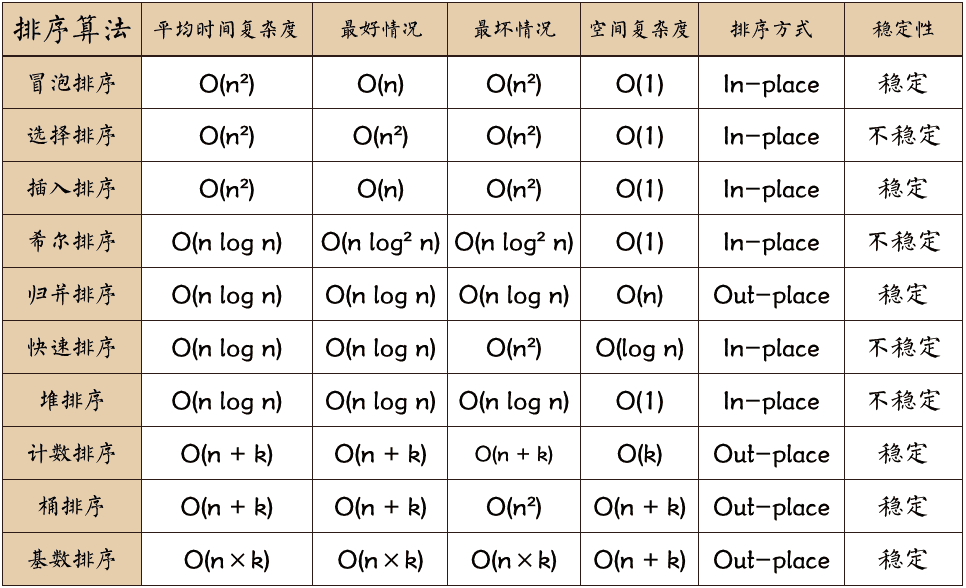
排序算法
排序算法排序算法说明排序的定义对一序列对象根据某个关键字进行排序
术语说明
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面
不稳定:如果a原本在b前面,而a=b,排序之后a可能会出现在b的后面
内排序:所有排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度:一个算法执行所耗费的时间
空间复杂度:运行完一个程序所需内存的大小
算法总结总结名词解释
n:数据规模
k:“桶”的个数
In-place:占用常数内存,不占用额外内存
Out-place:占用额外内存
比较与非比较的区别常见的快速排序、归并排序、堆排序、冒泡排序等属于比较排序。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置。在冒泡排序之类的排序中,问题规模为n,又因为需要比较n次,所以平均时间复杂度为O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为logN次,所以时间复杂度平均O(nlogn)。比较排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行 ...
回溯算法
回溯算法
二叉树
二叉树的基本理论从二叉树的总类特殊的二叉树主要有两种:满二叉树和完全二叉树
满二叉树满二叉树:二叉树只有结点为0的结点和度为2的结点,并且度为0的结点在同一层上如下图这棵树为满二叉树,深度为k时,有2^k-1个结点
完全二叉树完全二叉树:出来最底层结点没有被填满外,其余层结点数都达到最大,且最下面一层结点是从最左边连续最底层有1~2^(k-1)个结点优先级队列其实就是一个堆,堆就是一颗完全二叉树,同时保证父子结点的顺序关系
二叉搜索树二叉搜索树是一棵中序遍历有序的树
左子树上结点小于根结点值
右子树上结点大于根结点值如上两个都是二叉搜索树
平衡二叉搜索树平衡二叉搜索树: 也称AVL(Adelson-Velsky and Landis)树,它左右两个树的高度差绝对值不超过1,且左右两棵子树都是平衡二叉树。n个结点的平衡二叉搜索树高度可保持在 O(logN),搜索时间复杂度O(logN )最后一棵不是因为高度差绝对值超过了1.
java中map和set底层实现是红黑树,这个以后找个篇章特意写吧!
二叉树的存储方式
二叉树可以链式存储,也可以顺序存储。链式存储使用指针,顺序存储使用数组
...
开始
记录
无回顾,不成长